仕事上、割とSEOの相談や、コンテンツ作成の話はよく出ている中、ここ最近Chat GPT3系の話は非常に多くあります。
そんな中、オープンソースでないかなぁと思って探したらありました。
GPT-NeoX-20Bとは?
要は、最近のOpen AIで出ているGPT-3に似たやつのオープンソース版です。
EleutherAIの研究者はGPT-NeoX-20Bをオープンソース化した。これは、GPT-3に似た200億パラメーターの自然言語処理(NLP)AIモデルである。このモデルは、公開されている825GBのテキストデータでトレーニングされており、同様のサイズのGPT-3モデルに匹敵するパフォーマンスを備えている。
https://www.infoq.com/jp/news/2022/04/eleutherai-gpt-neox/ 参照
最近だと、Notion AIも出てくるなど、群雄割拠なので、どれが良いのか、というのを実施していきたいと思います。
早速使ってみる
先駆者お二方の記事を参照しながら、Google Colaboratoryで対応していく。
https://note.com/npaka/n/n09aeb00bf72b
https://qiita.com/syoyo/items/ba2c25a573ab8e338cd5
ColaboratoryをProに変更する
容量が大きかったりしてしまうので、とりあえず課金。
もしかしたら無料で動かすすべもあるのかもしれないけど、扱っている容量的には有料版にするしか道はなさそう。
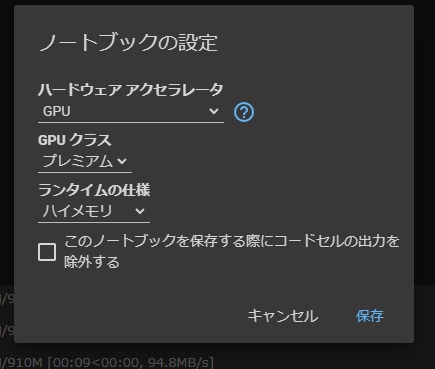
初期設定として、ランタイム→ランタイムの変更から、GPUをプレミアムにします。
コードを書いていく
先駆者がいるので、メインソースはありながら、そのまま動かしてもエラーログが出たので以下のように修正。
#
マウント
from google.colab import drive
drive.mount("/content/drive")
# 各種インポート
import os
!pip install transformers accelerate bitsandbytes
from transformers import AutoTokenizer, AutoModelForCausalLM
# トークナイザーの準備
model_name = "EleutherAI/gpt-neox-20b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# モデルの準備
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
load_in_8bit=True,
)
# 何回も動かすなら分割しても良いエリア ###
# プロンプト
prompt = """
ここに必要な文章を入れる
"""
# 設定
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
input_ids = input_ids.to('cuda')
output_tokens = model.generate(
input_ids,
do_sample=True,
max_length=2000, # 長さ設定
min_length=100, # 最短設定
temperature=0.9, # 文章の揺らぎ 0-2
num_return_sequences=1, # 文章数
)
output = tokenizer.batch_decode(output_tokens)[0]
print(output) # 必要に応じて別の吐き出し口にすることも検討ということで、結構時間がかかりますが、実行完了です。
何回も動かすなら、Colabのコードブロックを分割した方がスムーズに動くようになります。
今後
現時点では、GPT-3、OPEN AIのChat GPTやAPI、Notion AI、GPT-NEOX-20Bなど、群雄割拠な自然言語処理関連。
ただ、それぞれ得意不得意があると思うので、それをまとめていきながら各プロジェクトに合った実行方法を整理していきたいと思います。