自分用にも忘備録として書きます。
ちょっと仕事で複数テーブルの組み合わせを網羅的に出す必要がありました。
ただ、二つのテーブルをcross joinする方法はたくさんあれども、3つ以上のテーブルのcross joinってなかなか無かったのでメモしながら調べました。
動けばよい、という信条なのでコードとか汚くてすみません・・・!
やりたかったこと
Cross Joinとは、2つのテーブルのすべての組み合わせを結果として生成する結合方法です。
もしテーブルAが3行持ち、テーブルBが2行持っているなら、Cross Joinの結果は6行のテーブルとなります。

はい、ここまでは当たり前のことですね。
で、やりたいことはここからもう一つを組み合わせたい、ということになります。
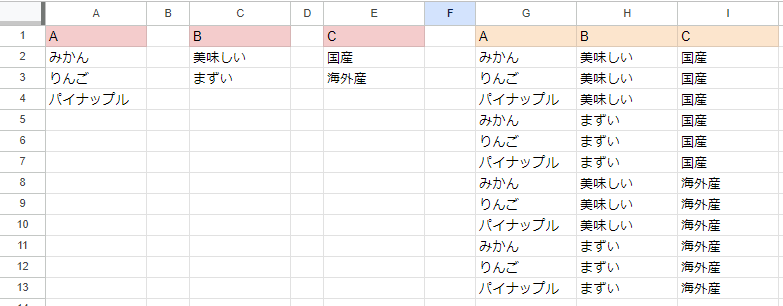
各パターンが少なければ手作業でもよいのですが、今回やりたかった組み合わせは約50,000通り。
スプシの関数も重すぎて動かないので今回はGoogle Colaboratoryを使いました。
実際に使ったコード
GoogleDriveへのマウントやCSVの読み方は割愛します。
最終的にはこうなりました。
#GoogleDriveのマウント
from google.colab import drive
drive.mount('/content/drive')
#CSVデータの読み込み
import pandas as pd
import numpy as np
data1= pd.read_csv('/content/drive/My Drive/temp/data/1.csv')
data2= pd.read_csv('/content/drive/My Drive/temp/data/2.csv')
data3= pd.read_csv('/content/drive/My Drive/temp/data/3.csv')
data4= pd.read_csv('/content/drive/My Drive/temp/data/4.csv')
data5= pd.read_csv('/content/drive/My Drive/temp/data/5.csv')
#CSVをクロスジョインしていく
d = data1.join(data2, how = 'cross')
d1 = pd.DataFrame(d)
print(d1)
d2 = d1.join(data3, how = 'cross')
print(d2)
d3 = d2.join(data4, how = 'cross')
print(d3)
d4 = d3.join(data5, how = 'cross')
print(d4)
#重複しているものを特定し、フラグを付ける
d4.loc[d4["1"]==d4["3"], "judge"] = "NG"
#フラグついたものを削除する
data = d4.drop(d4.query('judge=="NG"').index)
#確認print
print(data)
data.to_csv(f'/content/drive/My Drive/temp/data/data.csv', index=False)要は、読み込んだCSVをcross joinして、更にそのテーブルにcross joinをする形でどんどんと重ねていっています。
#CSVをクロスジョインしていく
d = data1.join(data2, how = 'cross')
d1 = pd.DataFrame(d)
print(d1)
d2 = d1.join(data3, how = 'cross')
print(d2)
d3 = d2.join(data4, how = 'cross')
print(d3)
d4 = d3.join(data5, how = 'cross')
print(d4)
で、ちなみに最後の重複については、自分がやりたかったのは特定の条件の組み合わせは排除したかったので
#重複しているものを特定し、フラグを付ける
d4.loc[d4["1"]==d4["3"], "judge"] = "NG"
#フラグついたものを削除する
data = d4.drop(d4.query('judge=="NG"').index)
でフラグを付けて、データから消すようにしています。
ということでやりたかったことが出来ました。
まとめ
Google Colabを使えば、大量のデータに対しても効率的にCross Joinの操作を実行することができます。
注意点としては大きなテーブルが生成されるかもなので注意が必要です。ちょいちょいチェックしながらやっていくことをお勧めします。
それでは!